
(ISC)² Security Congress 2022 - day two


Having woken up earlier than planned, I spent time pre-keynote watching talks from Monday. Not all the sessions I was interested in were ready yet (we were told it could take 24 hours), so there will be more for me to look at. I won't write about catch up sessions in my day posts but keep an eye out for additional posts on those.
Keynote - Cybersecurity Insights
Ciaran kicked off with a talk highlighting how we need to protect our digital assets and spaces as much as we do our physical spaces. He reminded us that during the Covid-19 pandemic lockdowns that we (largely) all went online, to cyberspace, to stay in touch with one another. Clearly the Internet is a key part of our lives, and we should protect it accordingly.
Part of the problem we have with the current setup of the Internet, is that original designers didn't expect it to be attacked or used for malicious purposes. This places security defenders on the back foot.
When looking to protect your own organisation, it's unlikely to be possible to protect all of it to the same standard. It was suggested there's nothing wrong with identifying your most crucial assets ("the crown jewels") and protecting those to a higher level than less important assets. Similarly, keep aware of global and industry events, and adjust the protection around your systems accordingly. If your network is well segmented, then you will be in a good place to help survive attacks where a third party moves laterally from asset to asset.
Keynote - number two
Unfortunately, due to the people involved and the topic, it's unclear to me what I am allowed to write about this session. In the interest of safety for the speakers, please understand that I won't write anything about this session.
How to Establish a (successful) Security Strategy from Scratch
This session served as useful validation for me, as both I and Esther (the speaker) seem to have started from similar places with our security programmes. Esther outlined a roadmap with five steps:
- Asset discovery
- Setting goals
- Workplan & budget
- Management approval
- Next steps
Asset discovery is necessary to ensure we know what we have to protect - often said and logically the right first step. I currently work for a company that's the result of several companies merging, so I am absolutely in this stage myself.
Setting goals and determining a workplan are really valuable but require an understanding of the risk and the business' objectives. A potential formula is:
Risk + Business Objective = Security Goals
Or more in English, determine the risk and how what the business objective is that means people want to take the risk. From there, determine what the security team needs to do in order to help the business minimise the risk.
Coming up with some key performance indicators will help you to track your progress. Importantly, don't just dive into the biggest task on the work plan - there will be some quick wins that you should consider first. An advantage of completing some of the quick wins is that others can see that you're doing something, and equally you may solve some pain points for them too. Your workplan should include goals for the first month, quarter, and year but be realistic about what you can achieve.
When getting management approval, be sure to use accessible language and explain why things need to be done in the manner you describe. There will almost certainly be changes to your plan or timescale, so try not to take it personally.
Underpinning all of this is the need to have good relationships with other teams and your colleagues. Through these relationships you can better understand where the business is going, or what they want to make things better. Esther reminded us that "As a CISO, you need others to get things done". This is a team effort.
Get real about Cloud Incident Response
An area that I'm aware my skills are lacking is cloud incident response. Almost all of my training so far has been based on responding to incidents relating to on-prem networks, so I was keen to attend this session to help plug that gap.
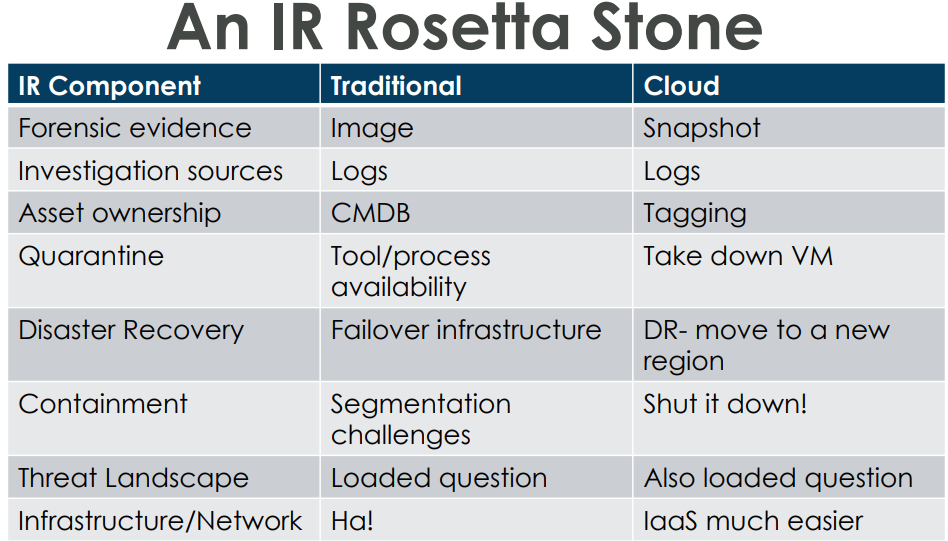
Something that Kristy mentioned right at the beginning is that once you move to the cloud, vendors use different terminology for the same things we use on-prem. In turn, that means that knowing which tool to reach for can be difficult. Kristy put together a "Rosetta Stone" [1] to help you translate the tool you'd want to use:
As with many aspects of security, you need to know what cloud services your organisation uses - everything from Infrastructure as a Service via one provider to Salesforce to Microsoft 365. As part of the exercise of identifying the solutions you use, aim to tag them appropriately so you can find the information asset owner. AWS certainly allows you to add tags to resources for this purpose. Once you know where your incidents could be, you'll be able to come up with appropriate plans.
When considering incident response, remember that misconfiguring something "in the cloud" can have wider impacts than making the same mistake on-prem, as cloud assets are often Internet facing. Your incident response plans should detail who is responsible for each area, how to contact them, and who at your cloud vendor to contact when the vendor's assistance is needed. Bear in mind that the vendor may not be expecting to talk to you, having always dealt with someone else.
During your response it's important to check the configuration is as you are expecting - avoid trusting the instinct of "I set it up this way, so that's how must still be". Infrastructure as Code can assist with this, as you can review the configuration as deployed (so long as you don't allow people to make manual changes).
Cloud providers often charge for bandwidth usage and copying logs down to your local machine will have a cost in both time (every second counts) and money. Kristy suggests having a virtual "crash cart" hosted in your cloud environment to save time and egress fees.
With the segregation of duties, it's likely the incident responder won't have administrative access to all areas of the cloud environment. That's appropriate for day-to-day scenarios but consider getting a break glass credential for when there's an immediate need to isolate something and your cloud team aren't available. Obviously there should be monitoring and alerting surrounding the use of such an account!
What it takes to build and maintain secure digital products?
Other speakers have indicated that security has traditionally been the last part of a product to be added, often meaning it's not done. In this talk, Sarba urged us to ensure that security wasn't just a feature of our products but was, instead, a foundational part of it. You can then communicate your products secure nature (not the specific protections themselves!) to your customers to demonstrate that you do place value on protecting their data.
The supply chain was also mentioned, and it's important to ensure you're always using the latest version of third-party components. Having a software bill of materials will also help with this, particularly when incident response is required, as you'll know if your product is impacted.
As a security team, being approachable came up again - it's important not to be feared by our colleagues. Collaborate with other teams to help strengthen relationships, which in turn will help others to consider security earlier on in the process.
Why Your Personal Infosec Brand Matters
First of all, it's important to realise that your personal brand isn't a marketing logo or similar, it's the immediate impression that others have of you. For an organisation, a brand is what its customers think of the organisation, and we all have customers too - the people we interact with. The speakers explained that your brand will have an impact on your likelihood of promotion or being successful in your job.
Being approachable came up again and we should be prepared to have voice conversations with people rather than just text-based ones. It's easy to read the written word the wrong way, or to spend many emails failing to communicate when a quick phone call would solve the problem. Having empathy with people is also important. A challenge one of the speaker's experiences, and I'm sure I suffer with too, is the fact that people will remember clearly when you're abrupt with them. As he put it: "did I help that individual or did I just with the argument?". Something I need to work on.
Your brand can result in you being "typecast" into a role, so if you're wanting to change role, or careers entirely, it's important to change your brand too. Remember that you have a "local brand", experienced by those around you, and a brand in the wider industry. The latter is increasingly important with increased working from home. You could choose to work in a completely different geography. Working on your wider industry brand can be accomplished by volunteering / mentoring or talking at event, amongst other things.
Avoiding Cybersecurity Achilles' Heels with Application Programming Interfaces (APIs)
My last session of the day looked at the security of APIs, with some interesting statistics. To start though, let's define Application Programming Interfaces (APIs):
APIs allow two or more users to communicate with each other (not users)
APIs handily allow applications to exchange data without the need to understand the backend systems that run them. For example, your application could use an API to request weather for a city, and so long as the request message follows the described format the API endpoint will provide an answer.
There's been a massive increase in API usage in recent years, and it's suggested each organisation interacts with around 15,000 APIs (either their own, or services they consume). APIs are used extensively with microservices.
Autoscaling is a popular feature of cloud computing that allows our applications to remain available even when under heavy load. As the load on an application increases, the cloud environment runs up additional instances to handle the load. If you fail to build request throttling into your API you could end up with a very large, unexpected, bill.
Much like handling data from forms in a web application, data passed to an API needs to be suitably sanitised, both at the endpoint (that will handle the request) and at the requestor's end (to ensure the response is not malicious).
There was a lot more in this session, and certainly plenty that I want to review at work, however, it's almost 01:30 here and I'm knackered. I'll end with a piece of advice from Andy: Ensure your APIs assume zero trust!
Banner image: Screenshot of the virtual conference venue landing page.
[1] The Rosetta Stone was crucial in translating Ancient Egyptian text: https://en.wikipedia.org/wiki/Rosetta_Stone
Accessible (text) version of the "IR Rosetta Stone" table:
+--------------------------+-----------------------------+----------------------------+
| IR Component | Traditional | Cloud |
+--------------------------+-----------------------------+----------------------------+
| Forensic evidence | Image | Snapshot |
| Investigation sources | Logs | Logs |
| Asset ownership | CMDB | Tagging |
| Quarantine | Tool / process availability | Take down VM |
| Disaster recovery | Failover infrastructure | DR - move to a new region |
| Containment | Segmentation challenges | Shut it down! |
| Threat landscape | Loaded question | Also loaded question |
| Infrastructure / Network | Ha! (Laughter) | IaaS much easier |
+--------------------------+-----------------------------+----------------------------+